Waarom zou je een ster schema data model gebruiken i.p.v. een platte tabel?
In de vorige post hebben we gekeken naar de definitie van een ster schema data model. Nu gaan we kijken naar een reden vóór het ster schema data model en tégen de platte tabel.
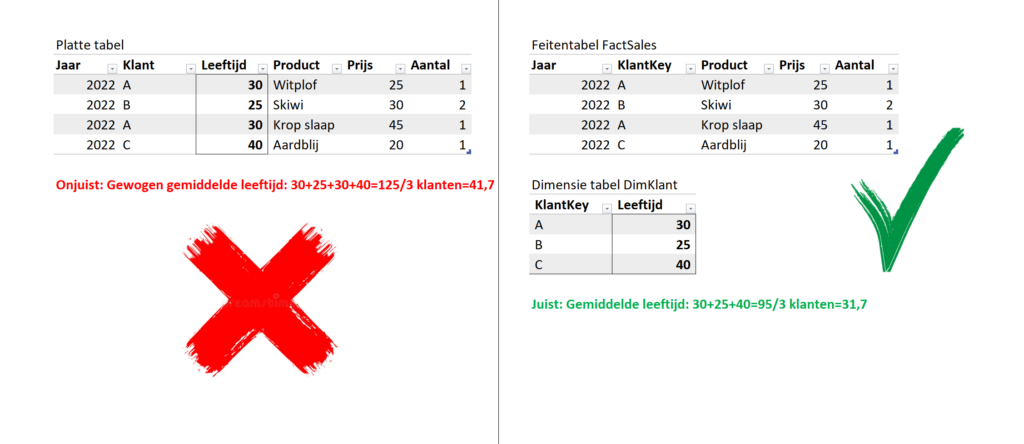
De eerste reden heeft te maken met aggregaties. Stel dat je een platte tabel hebt met transacties van verkopen waarbij elke regel een transactie is. Elke regel bevat tevens de leeftijd van de klant.
De afdeling Sales wil graag weten wat de gemiddelde leeftijd is van klanten in het jaar 2022. Vrij eenvoudig, je doet de volgende berekening AVERAGE( Sales[Leeftijd] ) en voila…. Of toch niet?
Wat nou als één klant meerdere transacties gedaan heeft in 2022? Die klant zal dan meer regels hebben in de tabel. De eerder genoemde berekening zal vervolgens ten onrechte een gewogen gemiddelde worden.
Dit is een reden om data die de context van de gegevens beschrijven te normaliseren, oftewel, weg te schrijven in een dimensietabel die via een kolom te verbinden is met de feitentabel (zie onderstaand).
Natuurlijk kun je dit probleem ook met DAX oplossen d.m.v. virtuele tabellen en een iterator (SUMMARIZE en AVERAGEX), maar het niet goed kunnen aggregeren van data is niet de enige reden om data te normaliseren en te streven naar een ster schema data model.
In mijn volgende post zal ik de volgende reden geven voor het ster schema data model.