Data pijplijn ontwikkeld met behulp van data build tool (dbt), Snowflake, Dagster en Github.
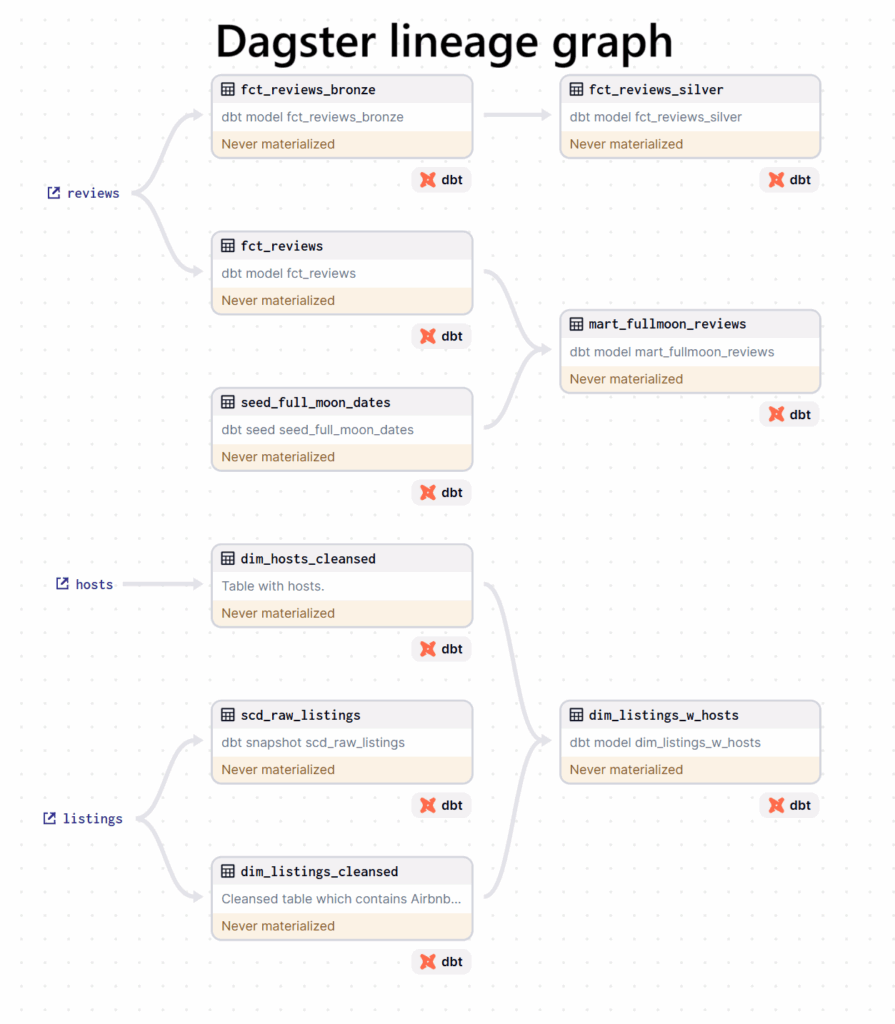
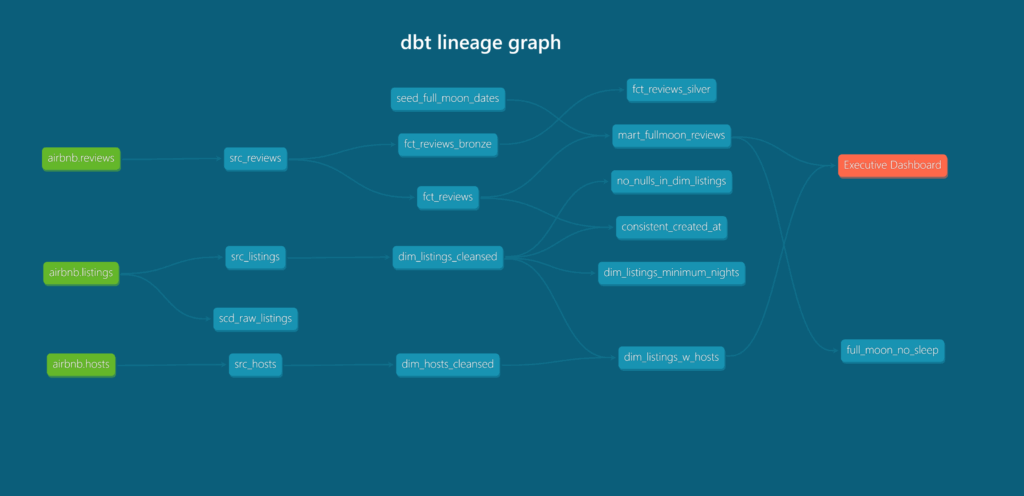
Er is een Medallion structuur geïmplementeerd met behulp van transformaties in dbt. Verder is dbt gebruikt om SCD2 te implementeren door middel van snapshots. dbt is ook gebruikt om generic en custom tests uit te voeren zoals het controleren van de kolommen op het bevatten van unieke waardes. dbt wordt tenslotte gebruikt voor de interne taakvolgorde van de dbt modellen.
Dagster wordt gebruikt voor de orchestration en scheduling. De keuze is op Dagster gevallen omdat Dagster gratis is en ook de mogelijkheid biedt om orchestration op een hoger niveau te bewerkstelligen; wanneer er bijvoorbeeld een Power BI Semantisch Model afhankelijk is van een object dat in Snowflake ververst wordt, kan Dagster dit middels de Power BI REST API verversen net nadat het Snowflake object ververst is. Dagster kan over de gehele data pijplijn de orchestration verzorgen.
Met behulp van een Dockerfile wordt een image gemaakt. Gebruik makend van deze image wordt een Docker container met een webserver gemaakt. Deze webserver heeft een UI waarop je Dagster via de browser kunt beheren.
Github dient als version control voor zowel het dbt project als het Dagster project.
Gebruikte tools: dbt, Snowflake, Dagster, Docker container, Github, SQL, Jinja en Python.